Maglev Hash: Consistent Hash with Guaranteed Even Distribution
In distributed systems, because there are too many requests to be handled by a single server reliably, requests are handled by a cluster of servers. In order to get high availability, the technique of distributing requests to servers needs to satisfy the following three requirements.
- Even distribution. Each backend take about M/N requests, where M is the number of requests and N is the number of servers.
- Low disruption. Adding or removing one server causes about M/N requests to be re-distributed.
- Affinity. The same request goes to the same server.
For the simplicity of explanation, we represent a request by a key and call the server a node. Distributing requests to servers now becomes mapping keys to nodes. The most commonly used technique of mapping keys to nodes is the Ring Hash, a.k.a., Consistent Hash. In this blog, we will look at an alternative technique, Maglev Hash, and discuss when it would be better to use Maglev Hash instead of Ring Hash.
Ring Hash
Ring Hash maps both keys and nodes to a number, called token, on a ring. The node assigned to a key is the first node found traveling clockwise from the key's token. It was first published at Using name-based mappings to increase hit rates and Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the world wide web. Ring hash is commonly found in distributed databases, e.g., data partition in Cassandra. In the following diagram taken from Cassandra documentation, there are 8 nodes and 8 token ranges.

Note that, nodes are not mapped on the ring evenly as shown in the figure above. Depending on the hash function, token ranges vary in size. In order to achieve even load across nodes, Ring hash introduced multiple virtual nodes to represent a node. Each virtual node covers a token range and a node covers all token ranges covered by its virtual nodes.
Maglev Hash
Maglev Hash was first introduced in Maglev: A Fast and Reliable Software Network Load Balancer as the consistent hashing to load balance Google's frontend services. It is also used in Cloudflare's Unimog Load Balancer and Rails Solid Cache.
Maglev Hash breaks down the key space to a fixed number of slots and assign slots to nodes. On adding and removing nodes, the assignment of slots to nodes is recalculated. Maglev Hash achieves even distribution and low disruption by assigning slots to nodes in the following way.
- Each node has a preference list of slots. For example,
a preference list of
[4, 0, 1, 3, 2]indicates the node considers slots in the order of slot-4, slot-0, slot-1, slot-3, and slot-2. - Iterate till all slots are assigned. At the each iteration, loop over nodes and try assign the node's preferred slot to it if the slot has not been assigned already.
The following diagram shows an example of assigning 7 slots to 3 nodes.
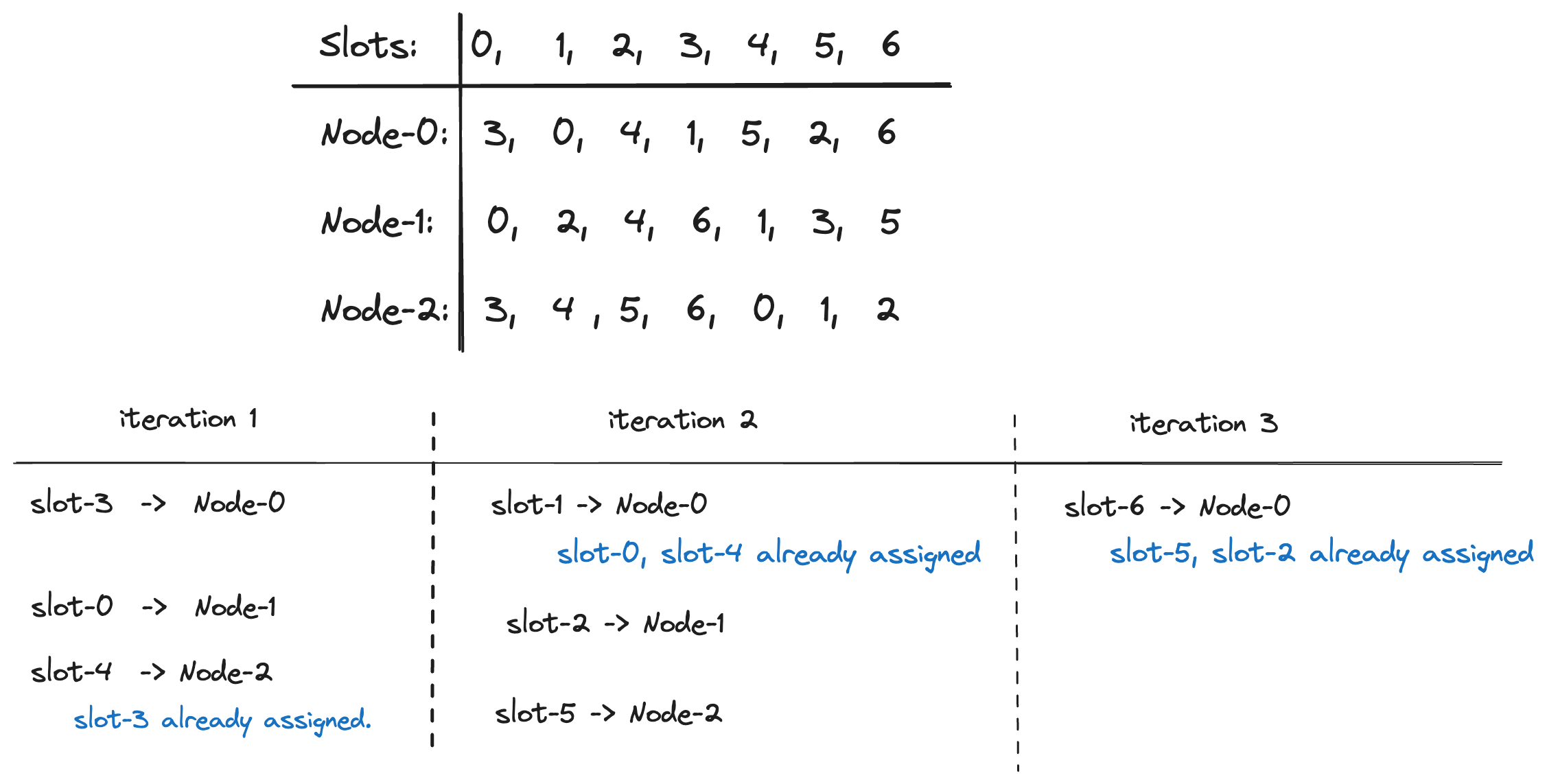

Let N be the number of nodes and M be the number of slots. Maglev Hash guarantees the following two properties.
- Even distribution. The difference between any node's assigned slots is less than N/M. For example, if M = 100*N, then the node with most slots has no more than 1% slots than the node with the least slots.
- Low disruption. On average, adding a new node causes reassigns M/N slots.
Experimental Results
You may have noticed that, how well Maglev Hash works depends on two things: the number of slots and the preference lists. In the paper, authors suggested choosing a prime number much larger than the number of nodes. Then using the following algorithm to generate the preference list for each node. h1 and h2 are two different hash functions.
1offset ← h1(node) mod M
2skip ← h2(node) mod (M − 1) + 1
3preference[i] ← (offset+ i × skip) mod M
I implemented the Maglev Hash at maglev.go. Then I ran two experiments with 10 nodes and 100 nodes respectively. The following diagrams show two metrics collected from the experiments.
- Coefficient of variation describes how even slots are assigned. Given an array of number of slots assigned to nodes, the coefficient of variation is the standard deviation divided by the mean. The lower the better, and the theoretical minimum is 0.
- Slot move overhead percentage describes the impact of removing a node. For instance, if a removed node originally had 100 slots, and the Maglev Hash moves 150 slots in total, then the move overhead percentage is (150/100-1) * 100% = 50%.
You can find the Jupyter notebook and the Go program used for the experiments.
Conclusion
Maglev Hash is simple to understand, easy to implement and excels in load balancing. I appreciate the simple concept of fixed slots. Redis also uses fixed number of slots, specifically 2^14=16,384, for partitioning. When comparing Maglev Hash with Ring Hash, Maglev does not need to travel clockwise on the ring. Traveling on the ring involves a binary search across all virtual nodes. Handling node removal in Ring Hash is also more complicated than recalculating the assignment and moving full slots. Since Maglev moves full slots, the overhead may be higher than that of Ring Hash. However, there are use cases where trading a little higher disruption for an even load is preferable. For instance, network load balancing and partitioning caches.